


{kind=link}
{kind=link}
前言
本篇是来自于2019年GDC失眠组AI程序员的演讲。讨论了在新的战斗系统下,AI开发组是如何解决各种问题的。
B站有我翻译的视频版https://www.bilibili.com/video/BV1314y1X778/?vd_source=65af2df2ff017c3bd67bbf746c2f29ca
包括:
- AI角色的行为编辑
- 利用同步动画实现具有漫画感的战斗
- 战斗系统的迭代过程
- 专门为本项目开发的程序化动画生成技术
- 还能提升的不足之处
AI角色的行为编辑
总结下来就是两个要点:
少用复杂的行为树
多用数据驱动的有限状态机
庞大的开发量
由于《漫威蜘蛛侠》战斗AI开发量相对于失眠组之前的项目来说大了太多,是失眠组当时为止规模最大的一款项目,而同时团队规模相较于上一款项目《日落过载》反而缩小了。
而在这种情况下,项目组需要为《漫威蜘蛛侠》制作:
- 5个主要敌人派系,及数个小型派系;
- 每个派系下的敌人有8中通用战斗风格,而主要派系下的敌人的战斗风格还有不同的变体,及派系专属的战斗风格;
- 11场boss战;

然后转化为AI的开发量则是64中不同的AI类,同时包含独特的攻击和其他行为,而对比团队规模更大的《日落过载》却只开发了19个AI类和17个行为树。
基础架构
自2012年起,失眠组就在基于C++的自研引擎中进行开发。AI的基本结构如下:
行为树生成包含子行为的行为节点,行为节点再输出角色状态。再由整个行为树控制AI的动画,移动及其他行为。
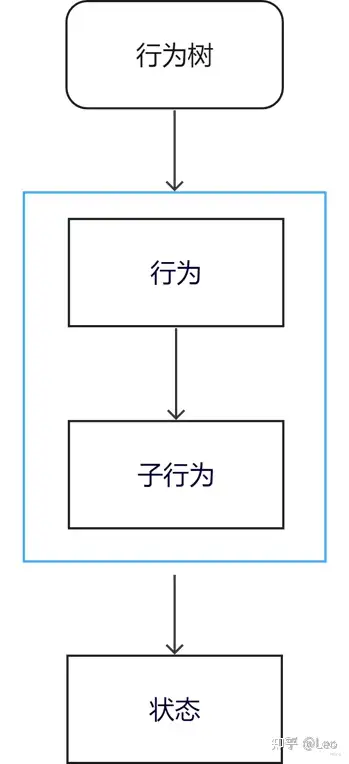
一个简单的结构图表
《日落过载》中的AI完全由这样的结构驱动,一个远程敌人的简单子行为树都会有34个节点,而其中多数节点都只输出简单的角色行为,如播放动画,闲逛,近战或远程攻击等。
这样的结构下设计师使用行为树配置状态参数,然后通过其中的行为只会输出一个状态实例。

《日落过载》中的一段子行为树
但这种做法也带来了很多问题。
首先仅仅一个简单的敌人行为,站在栏杆旁向外射击,就需要用到5个回调函数,这还只是该行为的一个

一大堆回调
其次是为了能让正确的节点在正确的时机被激活,就需要考虑如何让父节点选择运行正确的子节点。有三种选择方式:
优先级选择;
顺序选择;
返回数值选择;
而这种做法下的行为树就会出现非常多的修饰器,标识和其他搞不懂意思的选项。

问题
现在可以总结一下在过去项目的行为树架构下遇到的问题
- AI能正常运行,但结构过于复杂以至于出问题的时候很难查错;
- 节点复杂,以至于行为树结构下封装好的节点反而无法复用;
解决方案
- 使用更简单,更直接的行为树;
- 使用更复杂并且包含先前回调函数逻辑的行为;
- 标准敌人共用行为树结构和行为;
- 近战敌人的行为仅用一个节点就能实现;
随着行为愈发精确,数据驱动的占比变得越来越高,这样的解决方案被用到了游戏中的两种行为控制上:
设计师控制机器人通用行为时的脚本和战斗中的机器人行为控制;
这两种行为都在统一的AI编辑器中编辑,并转化为状态或子行为。
数据驱动的机器人行为
上面说到了失眠组摒弃了传统的行为树编辑模式而是利用更加数据驱动的解决方案,下面来看一下这种工作模式的高层架构。
脚本会首先创建一个机器人总控节点BotCommand,然后其中的命令将会传入到下一个节点,机器人命令序列BotCommandQueue中,序列生成后,行为树中编写好的行为实例将从命令序列中逐一拉出行为命令,最终再创建子行为或状态。
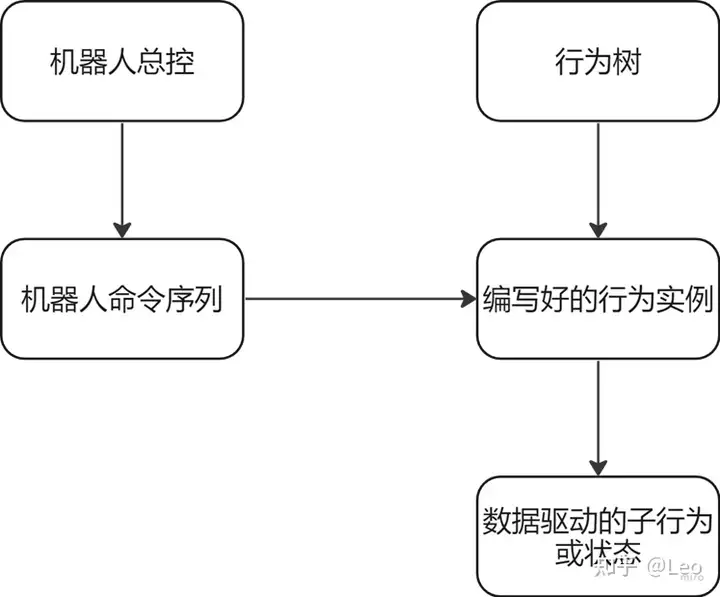
接下来逐个看一下每个节点的作用。
机器人命令序列BotCommandQueue
本节点的主要作用在于储存设计师发给机器人的指令,同时包含一个简单的交互界面。

机器人总控BotCommand
这一节点其实只是一个简单的界面,而实际对机器人发出的指令会使用StartBehavior这一方法启动其实际需要的行为或状态,再附加到其父行为上。

下面来看一个实例,此处列举了一个播放动画指令PlayAnim。
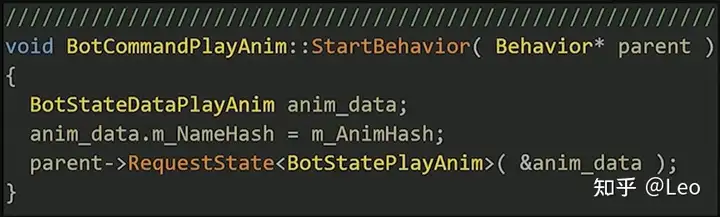
首先为播放动画状态设置一些数据:
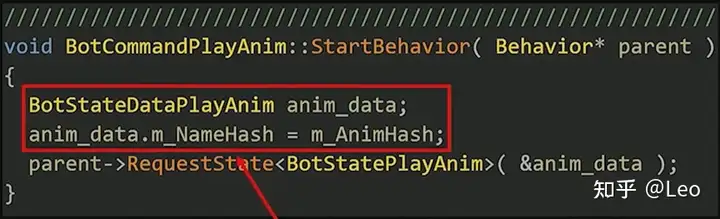
然后再把这一状态附加到相应的行为上:
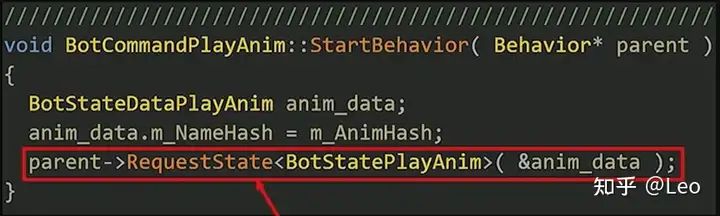
所有的机器人指令都遵循这样的格式,由脚本创建,并添加到机器人命令序列之中。
编写好的行为实例
如果机器人命令序列已经生成,并且其中已有指令,行为树则会将此行为实例化,其中包含一个Update函数,一个ConsumeNextCommand函数以及访问命令序列的句柄。
Update函数很简单,如果当前指令执行完毕,我们就将其从序列中弹出,然后再尝试执行ConsumeNextCommand函数。
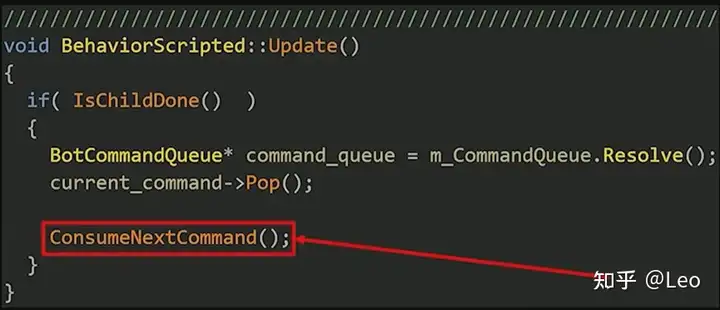
而ConsumeNextCommand函数同样也很直接,它先获取命令序列,检测其中是否还有命令,如果序列为空则停止运行,如果还有的话则启动该命令,再附加到父行为中。
命令结束后,之前的Update函数将再次调用ComsumeNextCommand函数,再继续执行各种命令。
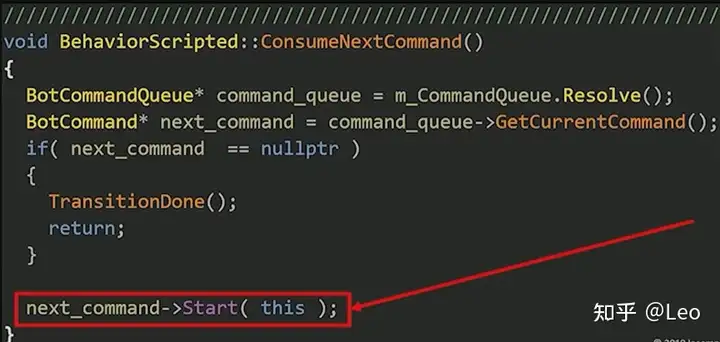
指令实例
发布指令在脚本里看起来就像这样:
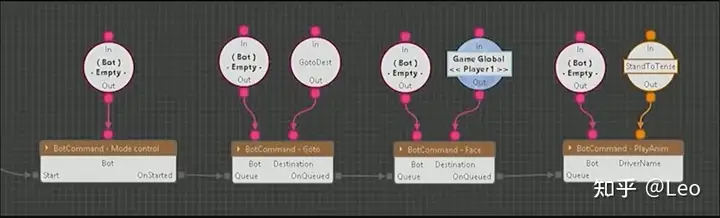
向机器人请求控制机器人→使其前往一个位置→面向目标→播放动画。
而游戏中的效果则是这样:

简单的行为控制,敌人从左跑到右再进入射击姿态
数据驱动的结构
在数据驱动的机器人行为架构下,有时机器人会出现很古怪的行为,下面来看一下驱动游戏中近战攻击行为的系统框架。
在数据层,每个机器人都有一套连招配置,其中包含这个机器人的连招列表,而连招列表又包含这个机器人的技能组合包,技能组合包则包含机器人的每一个基础技能。而这一系列数据全部从属于机器人连招组件。
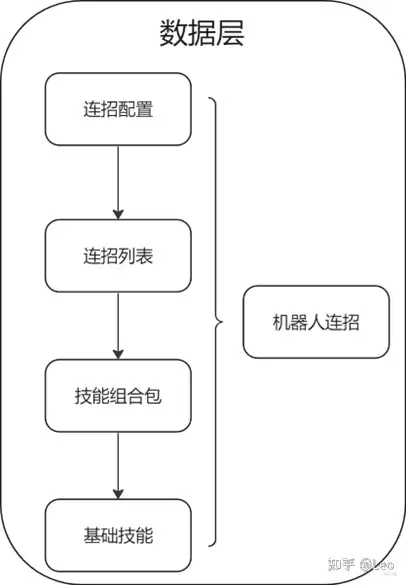
而在行为层,我们有行为树,它能生成近战攻击行为,当进入战斗状态时,这一行为将数据从机器人连招传到使用连招行为中,最终这一行为则利用这些数据开始一个子行为或状态。
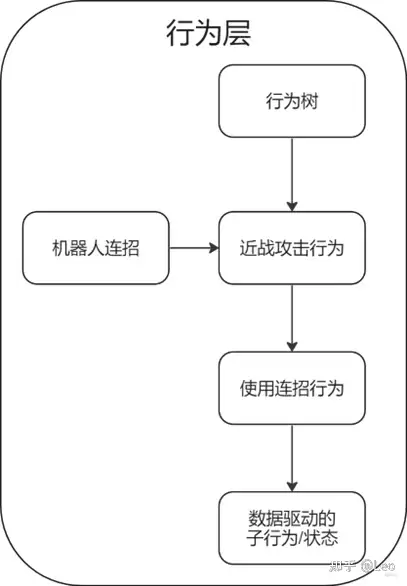
- 基础技能节点ComboMoveBase
所有攻击动作都源于机器人的基础技能,下面的结构表示需要执行的所有静态数据,比如现在执行一次近战攻击:
这套连招技能需要播放一套角色动画,以及一些数据用于控制具体释放攻击的时机。
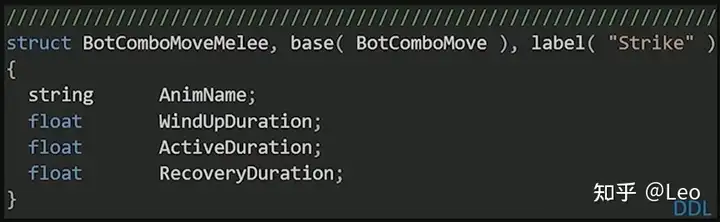
又比如现在机器人要发射一颗子弹:
该结构则会包含子弹本身的执行数据,机器人应该播放的角色动画,子弹从机器人身上的发射点位置,及一些额外的攻击时机数据。
也就是说,所有这些数据类型都包含开始攻击子行为/状态时所需的所有静态数据。即基础技能节点包含子行为/状态所需的静态数据。
- 技能组合包节点BotComboMoveContainer
此结构除了包含基础技能节点外,还包含其他数据,用于定义机器人应该如何执行各个技能,比如:机器人是否需要看到玩家后再执行技能,机器人是否需要处于屏幕范围内,以及释放技能时机器人和玩家间的距离。
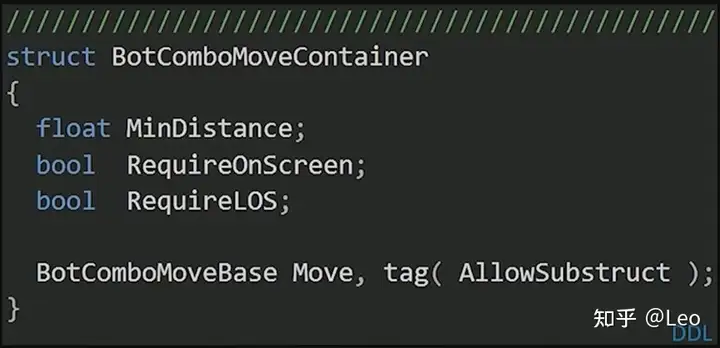
也就是说,技能组合包节点不仅包含连招技能数据,还包含用于驱动使用连招行为BehaviorUseCombo的数据。
- 使用连招行为BehaviorUseCombo
本质上只是一个状态机,它可以选择在原地等待攻击,前往某个位置,施展一次攻击,并在某个节点停止行为。
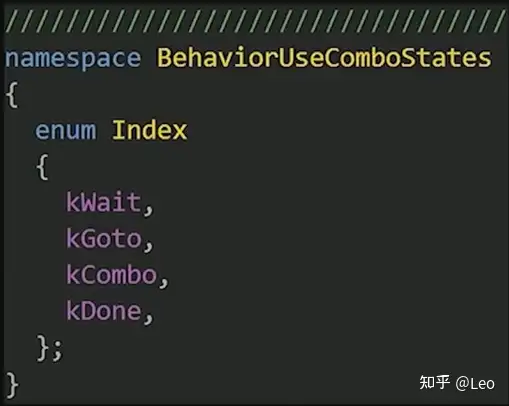
基于技能组合包节点中的数据,它可以决定机器人应该处于什么状态,同时也能帮我们实现一些效果,比如在敌人施展攻击时停止受击表现,以及在正确的时机让敌人的技能进入冷却。
而这些相关的代码只会在使用连招行为指定的时机才会执行,这时它会调用一个连招转换函数,这一函数从技能组合包中获取元数据,再根据不同的技能类型传入不同的状态数据,从而让机器人进入相应的状态。
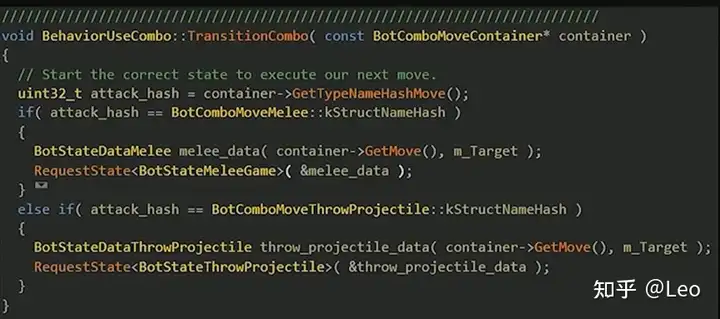
if else, if else…
在实际游戏中,失眠组利用这一结构处理了所有37种技能连招类型。
- 连招列表BotComboEntry
有时使用连招行为可能会在一个序列种调用多个技能,连招列表就包含其中所有的连招,同时包含其他数据用于决定何时这些连招才算有效。比如:冷却时间,连招权重,使用连招的最大和最小距离。
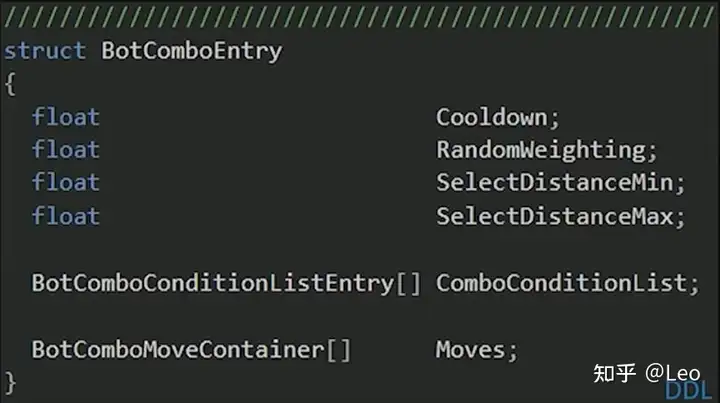
- 连招配置ComboConfig
它的结构十分简单,只包含连招列表信息。每个AI类,都有自己的的连招配置信息。
- 机器人连招BotCombo
不只是拥有连招配置,还负责针对当前目标从连招配置中选出最优的连招施放。此过程将利用连招列表中的所有数据,形成一套有效的连招,最后基于连招权重生成最终的连招序列。
- 近战行为BehaviorMelee
这一节点是一个标准状态机,也是实际使用连招的节点,如果到了该机器人攻击的时机,同时它又具有有效的连招列表的话,这一节点就会开始使用连招行为。
实际游戏中,使用数据驱动的近战敌人看起来就像这样:

右上角的debug信息可以看到当前正在执行的行为
从上层看这就是两大用数据驱动的AI模块:近战攻击行为和用脚本控制的敌人行为。
以及另外两个用数据驱动的重要模块:受击表现,另一个则用于响应即将来临的攻击,比如格挡,躲避,反击等。
优势与劣势
现在这种数据结构优势有三:
- 增加新技能很方便,因为不需要改变复杂的转换逻辑;
- 能更宽松地匹配状态和数据,一个连招技能能匹配多个状态,同时在合适的情况下,多个技能也能匹配同一状态;
- 能更好地筛选哪些数据可以开放给设计师,再去处理复杂的代码逻辑;
当然也存在一些缺点:
- 部分数据结构混乱,比如近战实例中出现的if else嵌套逻辑;
- 工具只支持将数据输出到属性面板
下面来看看为什么这一问题如此严重:
拿重型敌人的三连攻击为例,首先是一系列数据用于控制它该如何选择技能。
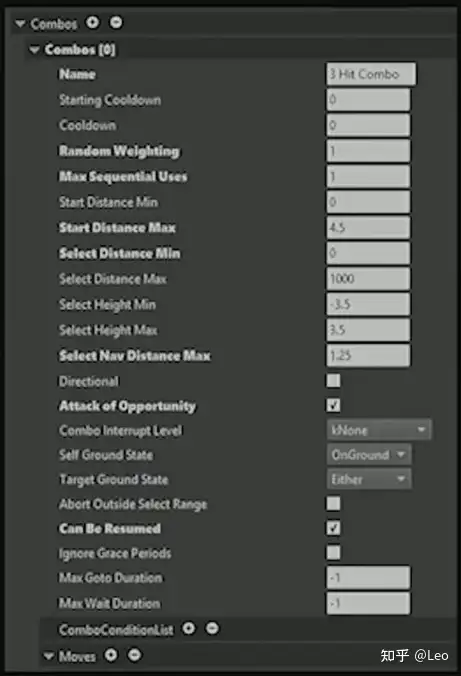
储存于连招列表中
然后是使用连招行为如何准备执行技能的数据。
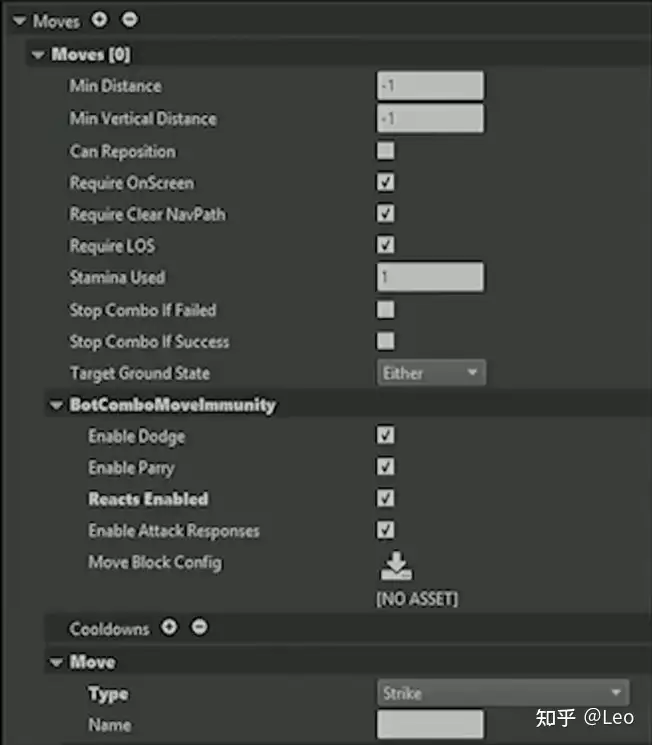
储存于技能组合包中
然后每次攻击还需要一堆数据,用于注册到“蜘蛛感应”中。
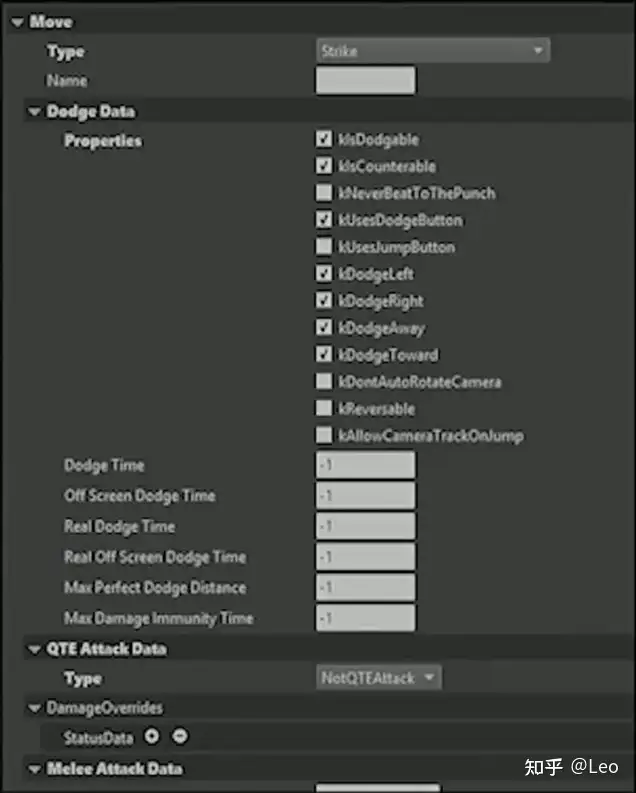
储存于基础技能中
然后需要近战攻击本身的数据。
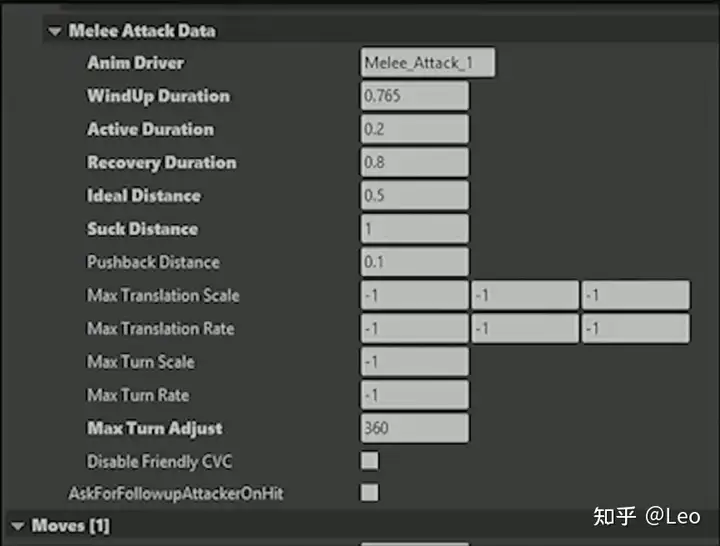
同样储存于基础技能中
上面也提到了这是一次三连击,那么所有这些数据都要重复两次以上。最终数据结构就成了下面这样:
除此之外这个重型敌人还有其他四个连招,所以这样的问题就是,整个数据结构变得,
- 配置量巨大;
- 数据结构难以理解。
同步动画
《漫威蜘蛛侠》的创意总监对游戏有一个要求,就是要有漫改电影的感觉,开发早期为实现这一目标,团队决定让游戏中的战斗动画和受击动画具有高度的真实感,于是开发了一个系统,用于播放蜘蛛侠和与其互动的敌人的动作。
其中的对象分为主体——通常为蜘蛛侠,也就是攻击的发起者;以及客体——通常是敌人,也就是被攻击者。
同步关节系统
同步关节是一个附加在攻击主体上的一个额外关节点,其中包含主体的位置和朝向信息,在和客体播放同步动画时匹配相关信息。

绿色代表主体的同步关节,白色则代表客体
实际开发中主要使用的是攻击发起者的同步关节,这样的目的是为了能让蜘蛛侠对还没有播放同步反应动作的角色发起同步攻击。
这里能看到蜘蛛侠和敌人身上的同步关节,随着蜘蛛侠施展攻击,其身上的同步关节也在不断地向目标吸附靠近。
此过程中蜘蛛侠其实并不知道目标会做出什么反应,如受击,格挡或闪避。实际开发中这里支持多种不同选项,以辅助蜘蛛侠实现其中的动作融合,包括人物的旋转和位移。

朝向对齐:主客体对齐
实际开发中最常用的对齐手段,下面的例子中,主体和客体间生成连线,并沿此连线的方向旋转并面向彼此。

朝向对齐:外部锚点
图中可以看到,两个角色同时转向外部的某个位置,这样做的目的是在蜘蛛侠使用投技时,能调整摇杆指,然后将敌人扔向指定的方向

位移对齐:主体锚点
用于客体进入目标位置的情况下,此时蜘蛛侠本身无法移动,图中能看到蜘蛛侠的同步关节处于外部的位置,然后敌人被拉扯到该位置。

位移对齐:客体锚点
此时蜘蛛侠施展所有位移动作,也是绝大多数攻击动作所使用的对齐策略,因为此时蜘蛛侠正主动进入目标位置。

处理高度差
很多时候攻击者和受击者的动画或动补信息之间可能存在高度差,有以下几种处理方式。
控制连接和释放点
所有同步攻击动作都标记有同步点和释放点,而带有表演镜头的潜行击倒和终结技,在角色到达同步点之前,摄像机将被拉近,用以隐藏漂浮在半空中的角色,等动画播放到释放点之后,再将摄像机推回原有位置。
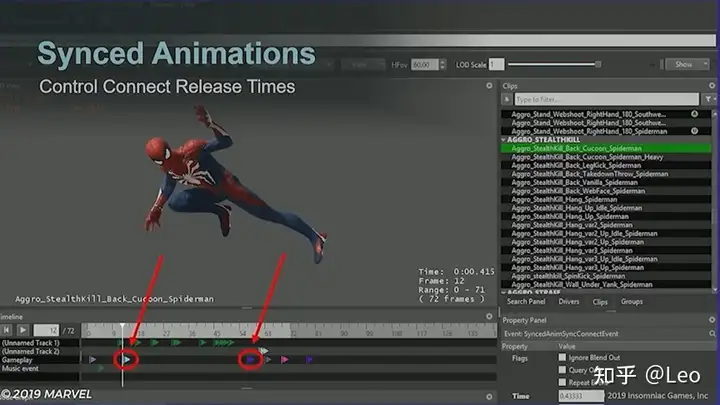
高度对齐:程序蛛丝
某些情况下可以使用蛛丝来处理不同高度下的对齐问题,比如下面的例子中,使用了预先制作好的蛛丝动画,再程序化调整每个关节的位置。

高度对齐:错误纠正
另一种很有用的做法是,将角色移动系统保持在开启状态,如果同步动画中的一方碰撞到了障碍物,它们将跳过在位移过程中无法执行的指令,下图中,蜘蛛侠与台阶相撞,无法完全和目标对齐,这种情况敌人将会直接向蜘蛛侠平移。
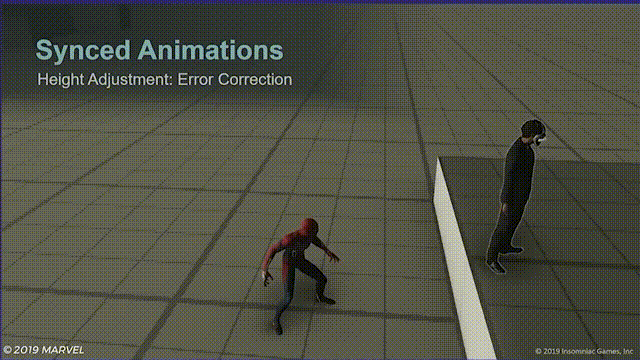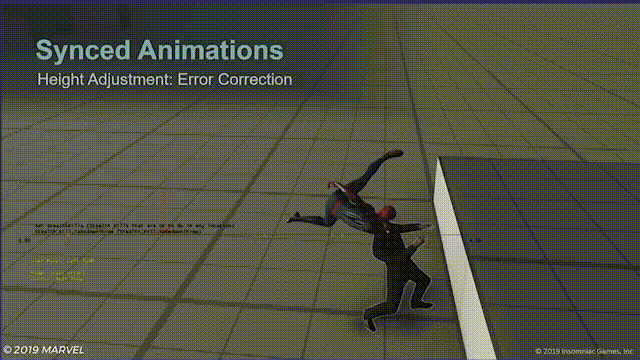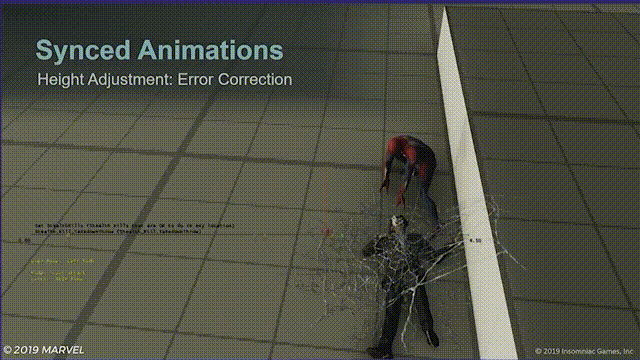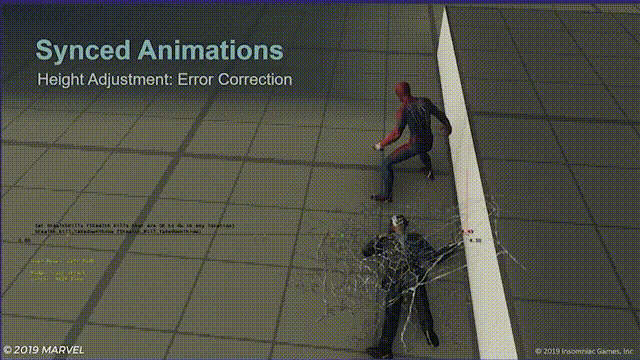
虽然很多时候都是在处理异常状态,比如下面这样:

敌人同步攻击
敌人同样可以对蜘蛛侠施展同步攻击,但这样的战斗会略显不公平,同步攻击用得越多,意味着受击方会更频繁地播放同步受击动画。

同步攻击的缺点
仅支持两个目标
无法支持蜘蛛侠一次性终结多个目标的需求。
添加新技能动作和骨骼变得更加耗时
每次添加新的骨骼都需要增加新的同步攻击动画。
战斗迭代
《漫威蜘蛛侠》中战斗的目标一直都是“高速,流畅,动感”,让敌人看上去具有威胁但又能让玩家打出流畅的连招成为了游戏战斗系统的关键。
下面将分享一下战斗系统的迭代过程。
战斗管理
首先希望管理敌人的攻击,并减少过于简单粗暴的连击,不然就会出现以下情况:

一场正义的围殴
游戏中有两个战斗管理器分别用于控制近战和远程敌人的攻击时机,它们有时会相互通信,但大多数情况下还是独立运作。
近战管理器
简单来说,就是通过不同的指令标记来告诉怪物何时发动攻击,近战管理器一开始很简单,只有两个指令标记:
- 攻击指令,但如果玩家刚刚进行了闪避,则不攻击,以让玩家有一个小小的喘息时间和反击窗口。
- 指令优先级,是一个用公式计算出的数值:
指令优先级=已等待攻击的时间+到理想攻击位置的距离+代表小型boss高优先级的额外数值
游戏中的效果就像这样:
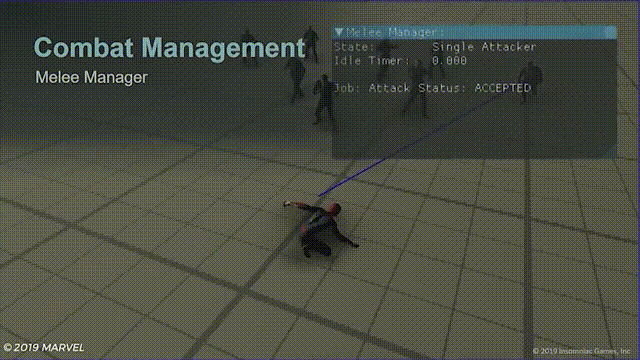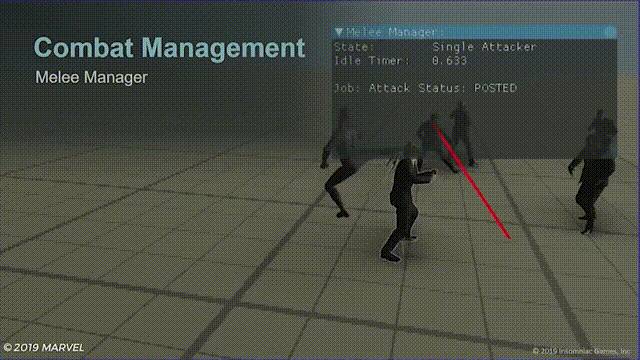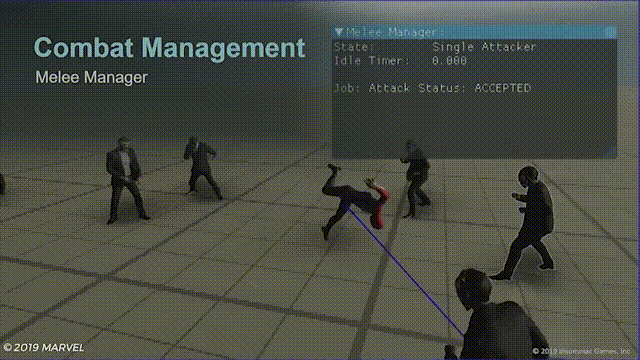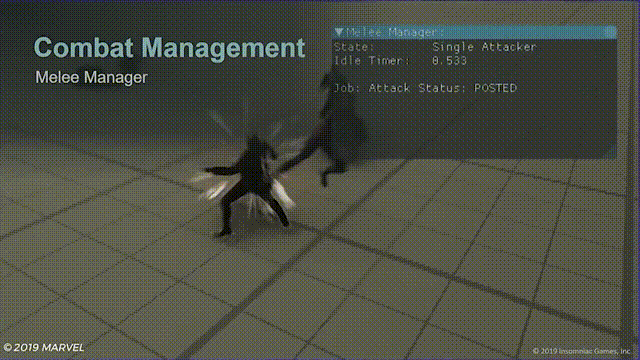
蓝色连线表示敌人收到了攻击指令准备攻击蜘蛛侠,左上角的待机计时器(idle timer),当蜘蛛侠使用闪避计时器就开始计时,给玩家短暂的攻击窗口。
近战管理器的问题
虽然看上去效果不错,还是会存在一些问题,比如玩家并不会在计时器规定的时间点马上就受到攻击,原因如下:
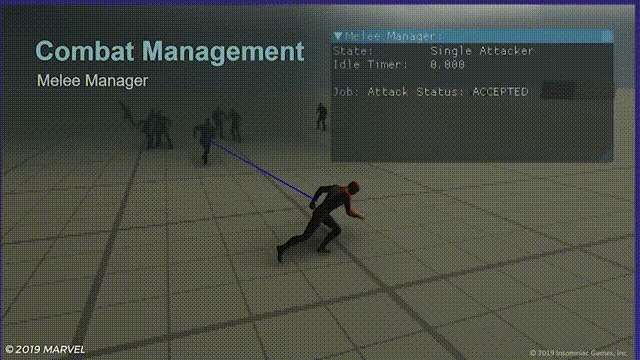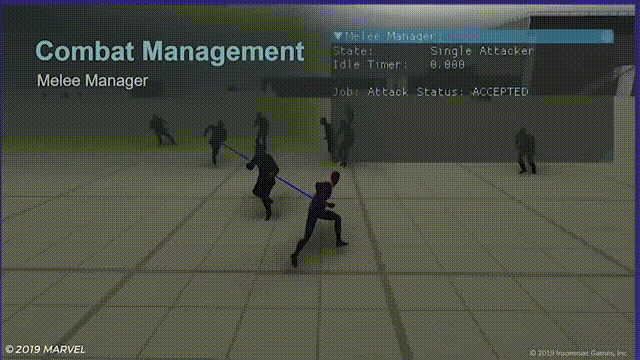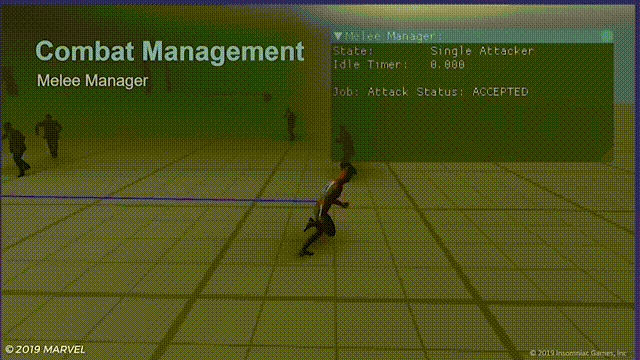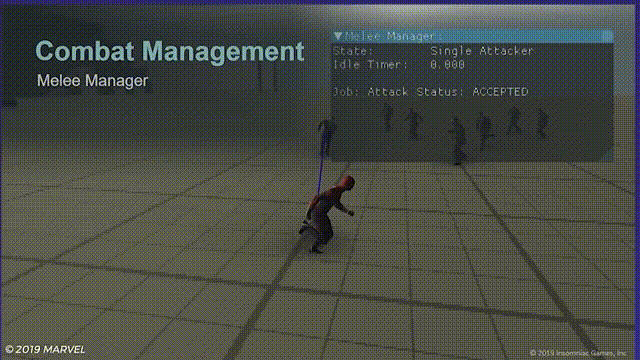
一个风筝的放
虽然这样的情况出现概率非常低,但如果玩家利用蜘蛛侠的灵活性在敌人之间来回穿梭跳跃的话问题还是很明显。
另外一个问题是,长时间的遭遇战会非常容易预测。
解决方案
- 指令窃取,如果场上存在一个能立即发起攻击的怪物和一个追击目标时间过长的怪物,那么此时则允许第一个怪物立即发起攻击;
- 近距离指令,如果玩家在一个距怪物极近的位置停留超过一秒的话,此时则允许指令管理器能创建一个新的指令。
加入这些功能后游戏中的效果就像这样:

可以看到在蜘蛛侠从敌人身边跑过时蓝色连线转移到附近敌人身上,然后立即发动攻击,战斗节奏突然静止时这两个新功能就非常有用。
- 加入战斗烈度计,敌人发动攻击时将累计计量表,然后当战斗管理器同时分发多个战斗指令或快速逐个分发指令时消耗计量表。
实际效果就像这样:

“Intensity”表示当前战斗的烈度;
下面的“Next Special”则表示发动下一次特殊攻击还需要累计的量表值;
“State”则表示下一次特殊攻击的攻击类型;
最下面的“Job”则表能看到实际被分发出去的攻击指令。
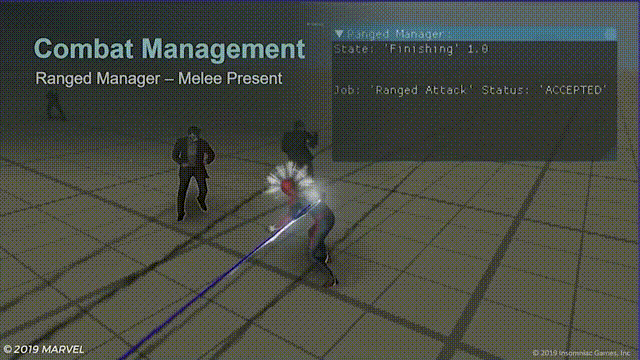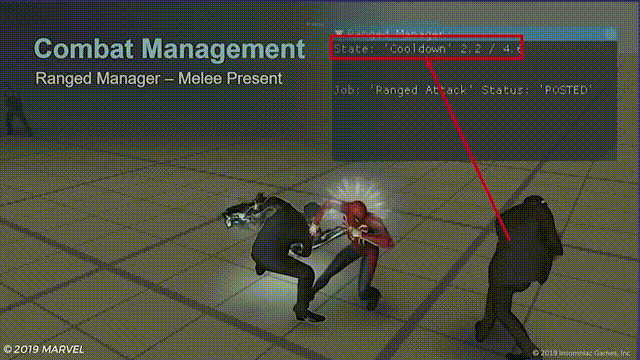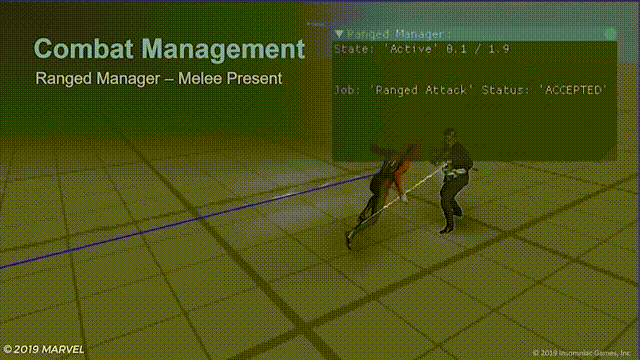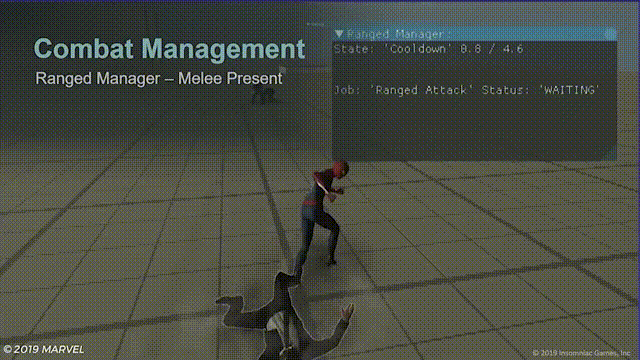
远程管理器
其实一开始也很简单:
- 攻击窗口,远程敌人能够收到攻击指令时生成;
- 指令上限,用于控制同一时间分发出的最大攻击指令数量;
- 延迟时间,用于避免控制器过于频繁地发出攻击指令;
- 冷却窗口,紧接攻击窗口之后,当没有远程敌人能收到攻击指令时生成;
游戏中的效果如下:

“State”处可以看到管理器在“冷却”和“激活”状态间来回切换,“Job”处则能看到攻击指令的状态。
远程管理器的问题
虽然如此设计不会有大问题,但一些情况下还是会让战斗显得不对等,最大的问题就是来自屏幕外的远程攻击。
并且当场上同时存在近战和远程敌人时场面会很混乱
解决方案
对于屏幕外的射击,初步解决方案是尽可能地只给屏幕内的远程敌人发送攻击指令,效果如下:
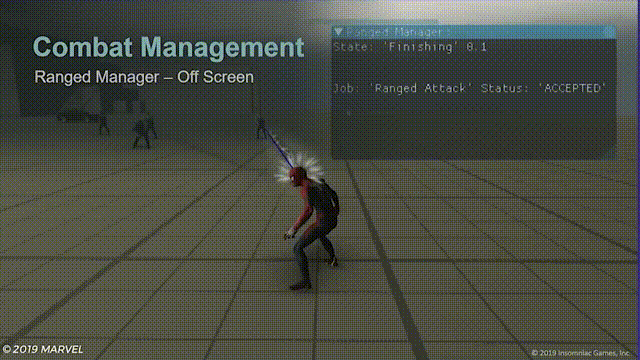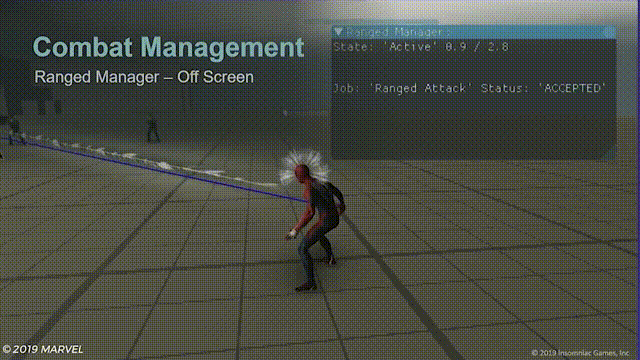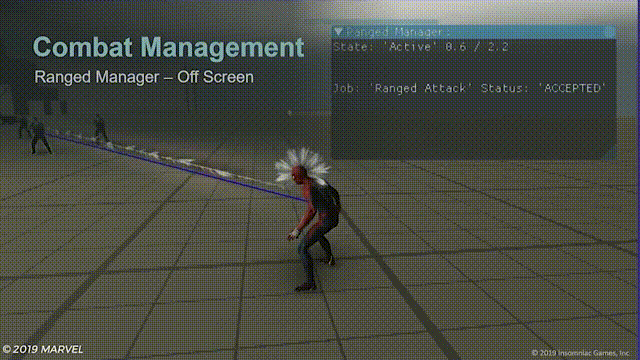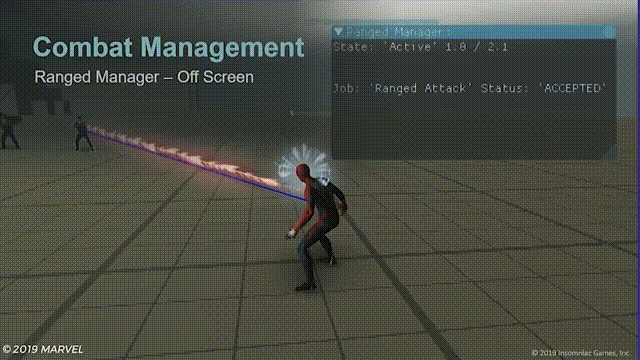
移动到屏幕范围之外的敌人将不会发动攻击
然而有时可能所有远程敌人都在屏幕范围之外,所以改成了让远程敌人处于屏幕范围外时具有更长的攻击间隔,这样一来给玩家蜘蛛感应的时间就会更长,效果如下:

当敌人在屏幕外时蜘蛛感应持续了1.5秒,而在屏幕内时则只有0.75秒。
而为了解决近战和远程敌人同时攻击的问题,设计师能指定一组新的数值,使敌人的活跃时间减少,并使每次攻击间的冷却时间增加:
但又出现了新的问题,如果将敌人的攻击冷却调长,当玩家使用空中连招时敌人就会显得很呆,差不多每5秒才会反应一次,而如果在空中连招状态下关闭新的数组,那么就会让空中连招感觉像是一种惩罚。于是引入了新的“空中进攻”系统。

- “Air Aggression Chance”,当玩家发动空中连招时,概率会逐渐提升,到0.5时周围的怪物将有50%的概率对玩家发动攻击。
- “AIR AGGRESSION ACTIVE”,表示敌人的空中进攻触发,对玩家发动攻击。
管理器问题
就算是多次迭代之后,玩家还是会感到自己非常容易受到攻击,于是制作组新增了一个列表,玩家执行其中的所有指令都会使战斗管理器取消所有还未执行的攻击指令,除非在boss战中,攻击指令都不会被取消,而如果玩家过度重复执行以下指令(闪避除外),管理器才会继续发送攻击指令。
- 使用蛛网投掷一个环境互动物;
- 使用蛛网打击一个新目标;
- 对目标使用上勾拳;
- 闪避一次攻击;
- 完美闪避一次攻击;
- 使用一次终结技;
- 跳过一个敌人;
- 跳跃;
- 落地;
- 受击;
先发制人系统
但这样还是不够,玩家还是会感到自己很容易受到攻击,比如下面这种情况:

此时玩家发动攻击想要打断敌人的攻击,但由于动画播放时间的问题还是会被敌人的攻击命中。

于是就有了“先发制人”系统(Beat-To-The-Punch),在动画打击帧时系统开启(红色球体出现),此时会检测每次即将来临的敌人攻击,并检测蜘蛛侠的攻击是否会强制敌人受击,如果能强制受击,在系统开启时蜘蛛侠在打击帧期间将免疫敌人的攻击。
实际效果如下:

双方同时发起攻击时,蜘蛛侠总是会优先命中敌人。
机器人定位和寻路
失眠组过去开发过很多射击游戏,在这类游戏中,机器人开火的位置会被提前标记好,同时利用体积检测标记出大块的地形阻挡,以便远程敌人能在掩体后射击,而近战敌人则只是尽可能地靠近玩家然后频繁地发起攻击,控制敌人阵型和输出空间也成了玩法的一部分。
而在《漫威蜘蛛侠》中,战斗需求则发生了改变:
- 让蜘蛛侠和大群敌人战斗但同时又不能让玩家觉得自己在持续被敌人围攻;
- 战斗不能只发生在开阔地形;
- 准备更多的AI类型并更加频繁地发起攻击;
- 战斗演出和表现要够华丽;
战斗区域环

第一次尝试是,在蜘蛛侠周围生成楔形区域,再以增加环形半径的形式使楔形向外扩散,然后检测楔形区域的寻路有效性,最后把机器人分配到最近的有效区域中。
问题
但并没有用,有两个原因。
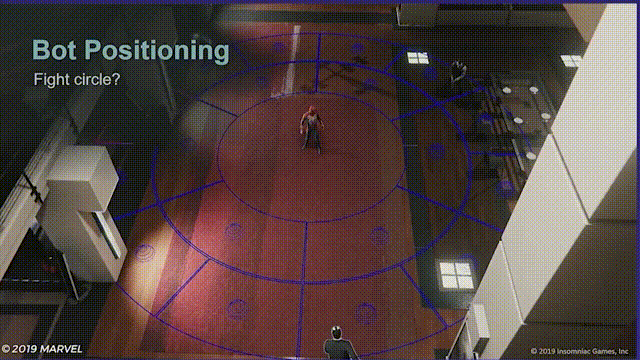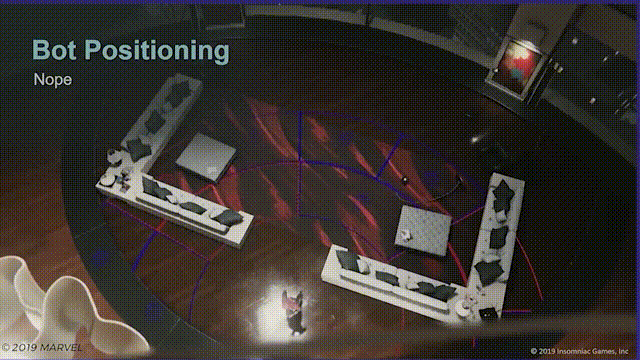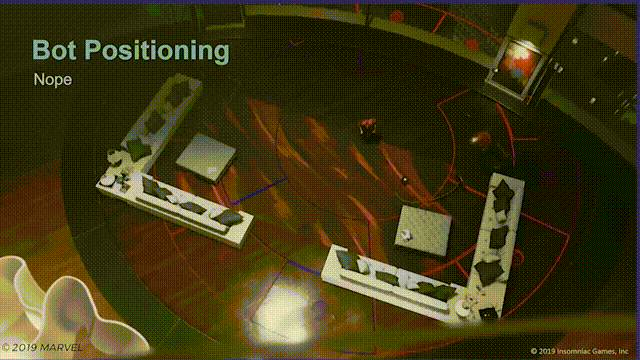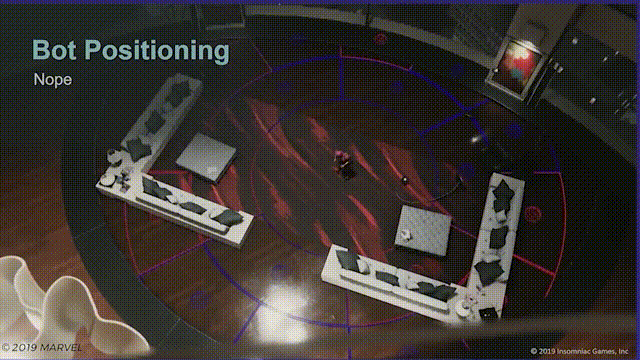
首先如图所示,玩家只需要在场景中不停移动就会使楔形区域失效,结果就是机器人会不断变换位置,而玩家并看不懂。
其次是表现不好,这种做法会使机器人寻路变得机械和固定,即使加入随机变量表现不尽如人意。
梯度下降算法
首先假设现在场上的阵型像这样,蜘蛛侠正面有两名敌人,一个远距离,一个中距离,然后侧面有三名敌人:
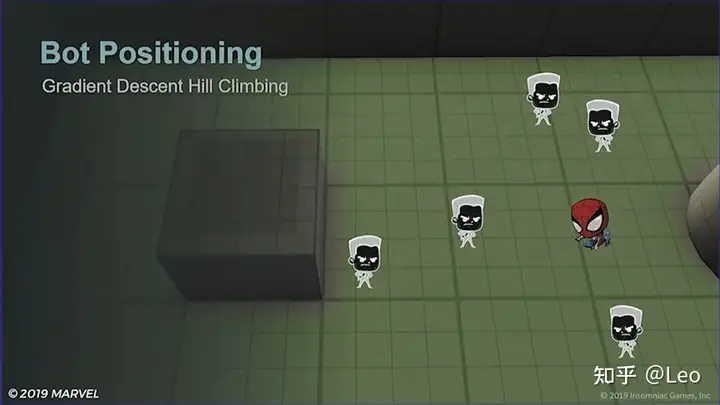
然后再假设蜘蛛侠和每个敌人都有一个代表个人空间的红圈,现在我们将其称为“机器人自留区“:
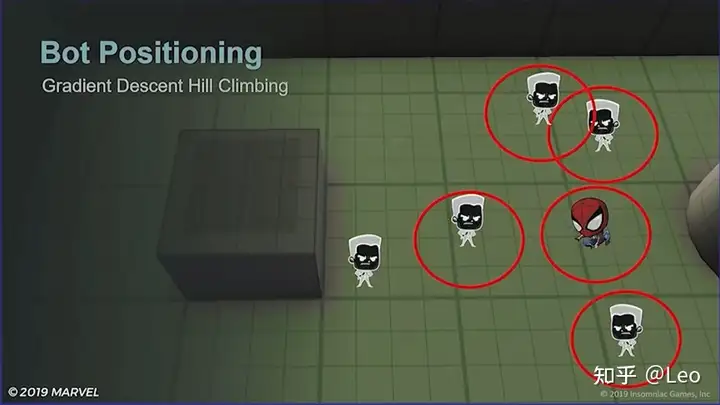
最后再加上NavMesh的边界:
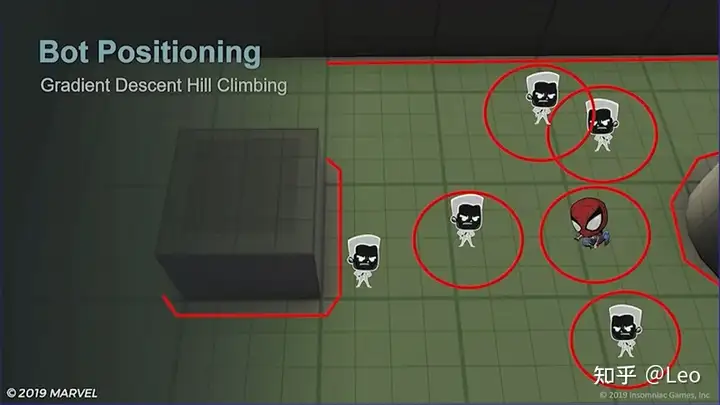
现在的目标是让机器人在红色区域外找到最佳位置。于是梯度下降算法便应运而生。
首先为了最小化能量函数的值,梯度下降算法每次迭代都会寻找梯度最陡峭的下降曲线,而在《漫威蜘蛛侠》的寻路策略中,能量规则是:
- 朝红圈中心移动时耗能会上升;
- 远离NavMash时其他所有位置的耗能都会归零;
然后每次迭代都将传入新的点,如果怪物当前位置处于红圈内,则会被朝圆心相反方向推到红圈之外,如果怪物处于NavMesh之外,则会被推到NavMesh范围内,就像这样:
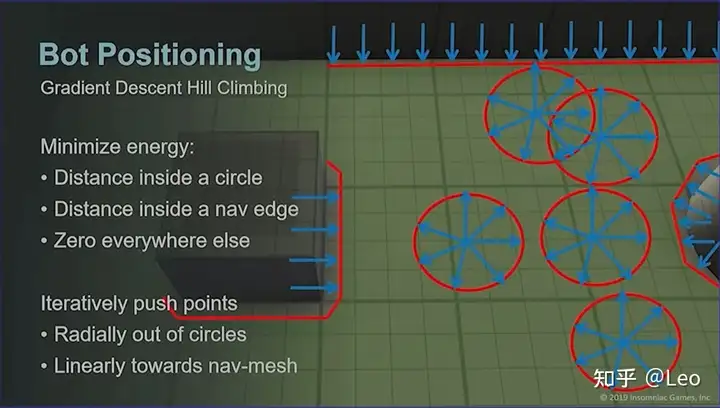
《漫威蜘蛛侠》中,梯度下降算法会一次性给敌人传入5个点:
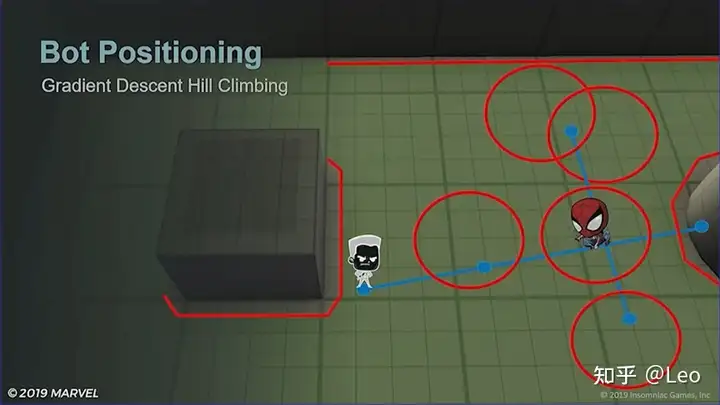
- 当前位置;
- 和当前目标连线,在目标前后各计算出一个点;
- 和当前目标连线后,再经过目标位置做一条垂线,在目标左右各计算出一个点;
然后梯度下降算法再对这些点做一些修改。
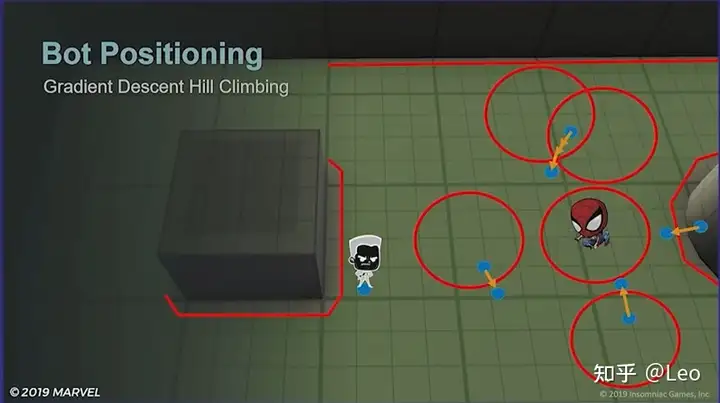
- 怪物当前位置,不会做任何操作,因为其已经在NaveMesh以内,红圈以外;
- 下方两个点,由于它们在红圈范围内,则会被朝圆心相反方向推到红圈之外;
- 远处蜘蛛侠背后的点,会直接被推到NavMesh以内;
- 上方同时处于两个红圈交接的点则比较特殊,首先会同时朝两个红圈的圆心反方向移动,但如果此时还处于红圈范围内,则会经历几次迭代后,移动到红圈外;
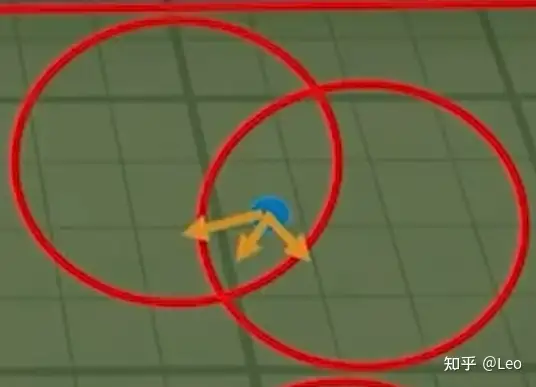
这样一来怪物便有了5个可选位置(蓝点):
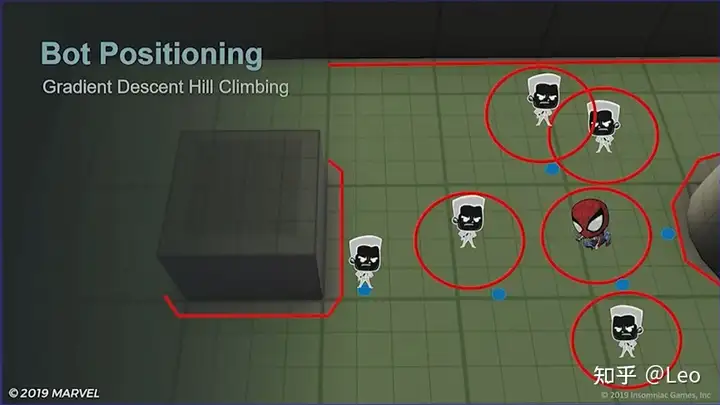
实际效果就像这样:

红色将头敌人使用了梯度下降算法寻路,机器人自留区显示为红圈,梯度下降算法的结果则显示为蓝色球体的运动轨迹。
生成5个点后,梯度下降算法将基于以下公式对每个点生成评分,然后再选择评分最低的点:

- DistanceCurrent:距当前位置的距离;
- DistanceTarget:距当前目标的距离;
- ClosePenalty:距离目标太近时的附加评分;
- FarPenalty:距离目标太远时的附加评分;
- CrossOverPenalty:前往新位置时需要穿过目标位置的情况下的附加评分;
混合方案
梯度下降算法在小型和中型遭遇战中表现很好,但大型遭遇战就会出现问题,其中标准近战AI的敌人尽量避免靠近玩家,就显得不那么有趣,特别是在增援刷新的敌人中,这个问题尤为明显。
为了解决这一问题失眠组恢复了部分战斗区域环的功能,不直接给机器人分配站位的具体位置,而是向其分配距离信息,再提供给梯度下降算法用以计算初始位置信息。

最终只有两个区域环,内圈为高优先区,最多能站6个敌人,外圈为低优先区,所有人都能站进去。
转移滞后问题
在散乱的战斗情景下,敌人转换位置时会显得不够自然,于是在机器人的行为层加入了最终检测机制。
首先检测当前位置是不是已经距离目标很近,如果是则不移动,如果不是再计算需要位移的距离,即“当前位置到理想攻击位置的距离-新位置到理想攻击位置的距离”。
然后再将需要位移的距离和不同的阈值比较,只有当“后退滞后值<需要位移的距离<前进滞后值”时才会进行移动。而阈值随时间不断变化,所以停滞越久的机器人将越可能开始移动。

同时还有一套类似的方案用以确定AI在移动时是否应该改变其等待位置。
首先取当前位置到等待位置的距离,再取当前位置到新位置的距离,然后取这二者之间的距离,这三个点的距离都要大于阈值,以更新目的地位置。
程序化动画——蜘蛛网和鞭索
游戏中希望蜘蛛侠能用蛛网把敌人困在物体表面上,但游戏中很多表面并不平整,结果就是由于布娃娃系统,机器人可能摆出各种奇怪的姿势。
为了解决这一问题,失眠组在游戏中生成空间定位,再将其信息传入到“网毯”系统中。
网毯
网毯是一个蛛网模型,具有6*6的格子关节,如图所示地展开并锁定。
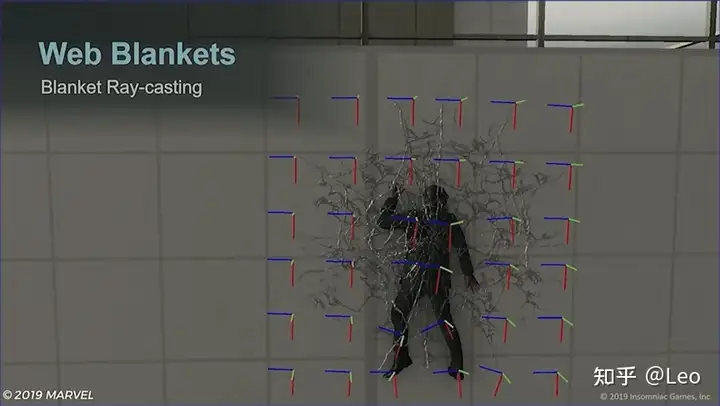
生成时,网毯会从生成位置上方发射射线,如果蛛网模型被简单地 摆放在生成位置,那射线就会穿过每个关节所在的位置,射线命中的位置,就是关节附着的位置,也就是图中的橙色射线:

如果射线没有命中任何物体,系统则会将射线向网毯的初始位置旋转,通常情况下这么做会将网毯向附着的物体上包裹,同时关节在完全定位前还能持续扫描一段时间,这样网毯能适配当前的布娃娃或正在播放动画的角色,而不会缩成一团。

当网毯附着的对象移动到了离初始位置太远的位置,此时也能让关节重新扫描,比如下图中的情况,这样是为了避免网毯随着这个车门被拉得整个关卡都是。

鞭索
游戏中设计了集中使用鞭索的敌人,随后制作组发现常规的衣物模拟无法满足需求,同时因为还要复用其他职业的敌人动画,所以也不能直接给鞭子制作动画。于是便有了一套程序化的解决方案,并且在必要时还能完全使用动画控制。
限制器
鞭子本身是模型的一部分,并且在动画工程中还未添加动画时看起来像这样:

开启模拟后则变成了这样:

系统会逐帧追踪每个关节的位置,然后直接把主节点的运动应用到每个关节上,然后再引入限制器。
- 距离限制器,使用一个0-1的硬度参数并沿链条方向向上和向下两个方向运行,每个方向各运行一半错误矫正。这样能保持子节点和其父节点对齐,不然就会出现下面的问题:

- 弯曲度限制器,用以纠正链条根部水平放置时链条下垂的问题。将每个关节同时限制在其父节点和子节点范围内。
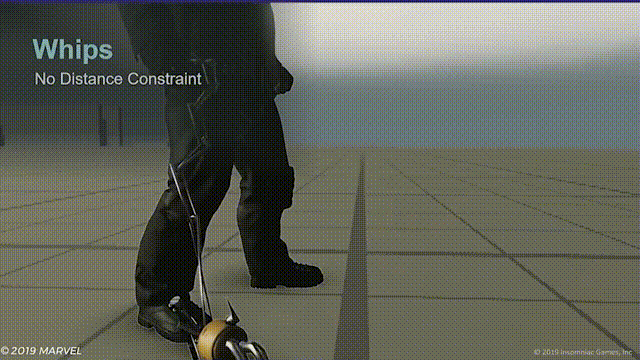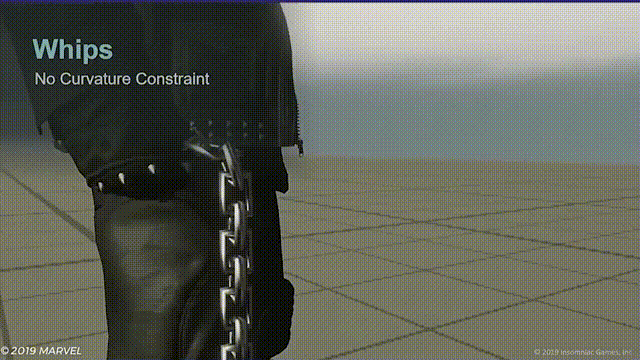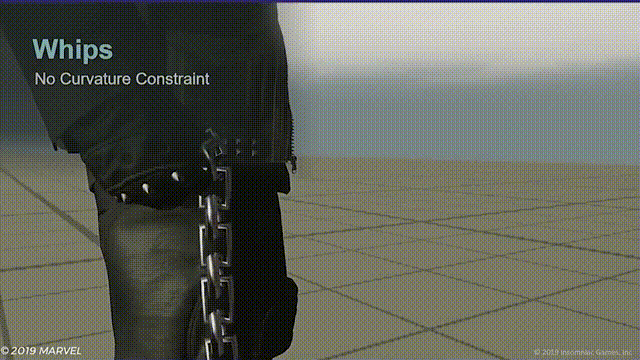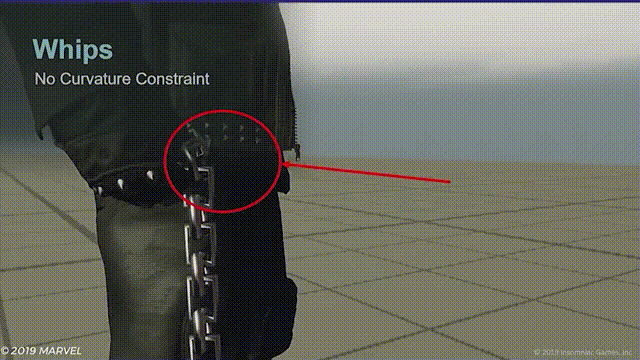
两个限制器同时作用能有效避免链条打结的问题,并且弯曲度限制器能使模拟关节比动画关节更加平滑。
- 重力限制器以免链条飘起来:

- 地面限制器防止链条陷入地面:

- 胶囊体限制器,用于防止链条穿过角色本身:

使用前

使用后
实际使用顺序是,中立→弯曲度→胶囊体→距离→地面。
控制
不论是模拟驱动或是动画驱动,一开始都将其假定为模拟驱动,然后再在动画轨道上添加事件,以控制链条在什么时候应该被转换为动画,而又应该在什么时候转换回模拟控制。这些事件还包含融合速度,用一个0-1的数值控制,代表链条用模拟控制的百分比。没有任何一个关节会同时由模拟和动画控制。
动画轨道和事件节点
程序化对齐
鞭索类敌人的一大设计目的是能把蜘蛛侠困在原地或将其从空中拉下来。所以需要在敌人播放攻击动画的同时,将鞭索的动画融合到任意世界位置上。
鞭索上的每一个关节,如果敌人和目标完美对齐的话,系统都会计算它们下一步的位置。计算前后两个位置的区别在于其浮空高度。然后将部分浮空高度应用到动画控制的关节上,以改变其原本程序对齐生成的位置。浮空对齐比例随着链条关节离发射点越远而线性增长。

一些纠缠已久的问题
最后一部分是一些给制作组带来很多麻烦的问题。
飞行敌人
在开发喷气飞行兵和两个飞行boss电光人和秃鹫时,遇到了很多问题。
首先是NavMesh问题,由于这些是飞行敌人,它们会漂浮于NavMesh之上,然后如果它们的目的地在事先范围内的话它们能飞到NavMesh范围外,此时这些飞行敌人会保存一个路店列表以寻路返回到NavMesh范围内,但即使如此在游戏中还是能看到它们绕着地面物件一直转圈。
下面是一个例子,这个喷气飞行兵要接近蜘蛛侠,红色胶囊是它到蜘蛛侠位置的物理检测,查看它能否直接飞到目的地。

而由于这个红色胶囊检测到了墙体,它就必须要沿蓝色的路线绕过篱笆直到它真正看到蜘蛛侠。

结果就像这样:

而电光人和秃鹫这样的飞行boss,它们使用一组样条连接的体积集合,在体积范围内boss能完全自由活动,然后他们能利用样条在体积之间切换。但问题是这些数据都必须手动生成,所以并不完全通用。
移动的平面
游戏里有在诸如移动的卡车上发生的战斗,这种设计带来了很多问题。
首先由于NavMesh无法移动,所以战斗的区域只能尽可能地做得简单,以便boss能更简单地靠近蜘蛛侠。
然后很多状态和组件运算都基于世界空间坐标,当这些位置不能每帧对齐的话就会出现很多bug。
另外失眠组的引擎还不像unity或者虚幻那样支持附着物件,所以只能用专用的部件手动更新所有的附加实体。
最后被扔下卡车的敌人或玩家如果正好和卡车相撞的话,会和卡车穿模,所以只能在卡车移动时在卡车旁边添加杀伤体积。
NavMesh
问题
制作组添加了不少新功能,比如动态裁切,这样就能实现停车和其他很多犯罪行为。然而游戏设计则需求曼哈顿随着故事推进实时地发生变化,同时也希望将蜘蛛侠的状态变化反映在世界上。
而NavMesh是在预先切分好的场景分区上搭建并加载的,此时需要根据不同的游戏状态加载不同的NavMesh数据,那么就必须在搭建阶段就表达出所有这些状态。当然制作组也不是没想过在游戏运行时生成NavMesh数据,但CPU消耗过于高了。
解决方案
生成最复杂的NavMesh数据,并通过脚本根据需求禁用部分数据。
具体做法
首先是游戏第一章时的情况,这里能看到NavMesh的补丁漂浮在空中,而黄色补丁则是设计师想要利用脚本控制NavMesh开关的地方。还能看到本该在第三章中出现的物件切出的空洞区域。



而到了第三章则变成了这样,能看到原本第一章场景中预留的NavMesh补丁位置都出现了对应的物件。


CPU性能问题
在开放世界中运行各种复杂的AI还是会遇到性能问题。解决方案是将。最大活跃地人数限制为30个。
主要有两个原因,首先是物理层面,下图是一些性能明显下降的关键帧,红框部分是由于机器人数量增加而导致性能骤降的问题帧,上方是主线程,下方是四个工作线程中的两个。
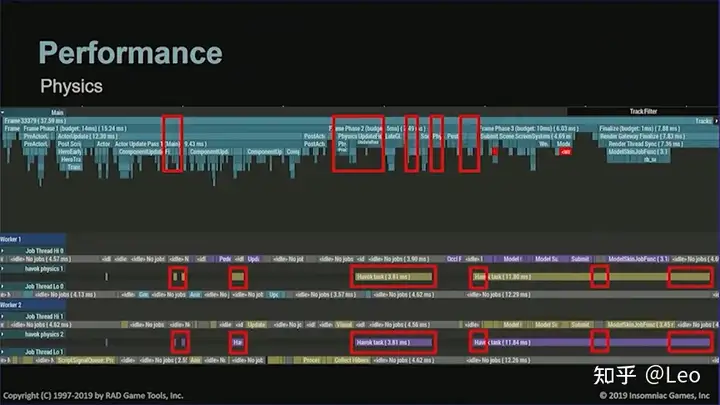
这是由多个核心分摊运算累加的很多毫秒,虽然不全是直接由单个机器人产生,但确实随着机器人数量上升而逐渐上涨。
还有个问题是,很多核心AI逻辑仍然在主线程上运行。下图是主线程在常规帧下的运行情况,红框区域是机器人的具体逻辑,它们会消耗远超4毫秒的时间,如果考虑到还要加入角色移动系统和动画系统的话则会消耗更长的时间。

总结
演讲到这里就结束了,总结一下本次演讲的关键点。
- 迭代为王
- 新问题需要新方案
- 专注于核心玩法
暂无关于此日志的评论。